|
|
java 字符串以及其他知识
字符串
从概念上讲,Java字符串就是Unicode字符序列。java没有内置的字符串类型,而是在标准java类库中提供了一个预定义类,叫做String。每个用双引号括起来的字符串都是String类的一个实例:
String e = ""; // an empty string
String greeting = "Hello";子串
String类的substring 方法可以从一个较大的字符串提取出一个子串,例如:
String greeting = "Hello";
String s = greeting.substring(0, 3);这就创建了一个由字符 “ Hel ”,组成的字符串,substring的第一个参数是指从零开始,第二个参数指的是不想复制的第一个的位置,因此s这个字符串得到的结果是 “ Hel ”,也就是从0开始但是不包含3
计算子串的长度也很简单,就直接3-0=3
拼接
java语言允许使用“ + ”连接两个字符串
String expletive = "Expletive";
String PG13 = "deleted";
String message = expletive + PG13;结果就是“ Expletivedeleted ”
当一个字符串与一个非字符串的值进行拼接时,后者被转换成字符串,例如:
int age = 13;
String rating = "PG" + 13; //变成了 “ PG13 ”如果需要吧多个字符串放在一起,用一个定界符分隔,可以使用静态join方法:
String all = String.join("/", "a", "b", "c", "d");输出的结果为:a/b/c/d
不可变字符串
注意,在java中,我们申请完java字符串后,java字符串就是不可改变的
比如
String str = "abcdef";那么这个str就是不可改变的,java编译器不允许其发生改变
虽然字符串是不可变的,但是字符串是可以共享的,java的设计者认为共享带来的高效率远远胜过于提取、拼接字符串所带来的低效率
字符串与内存
本部分主要参考博文https://zhuanlan.zhihu.com/p/159443898
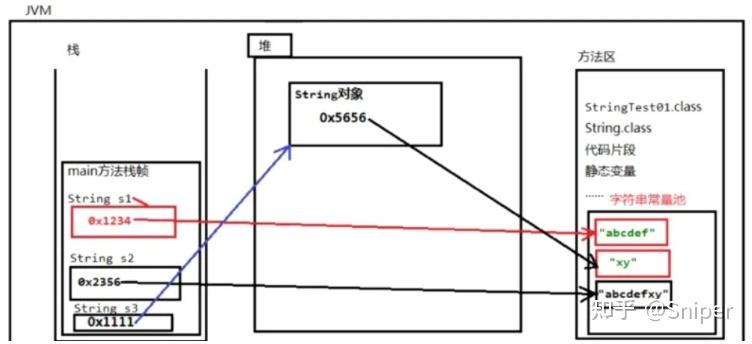
首先由两个概念:①栈:由JVM分配区域,用于保存线程执行的动作和数据引用。栈是一个运行的单位,Java中一个线程就会响应由一个线程栈与之对应②堆:由JVM分配的,用于存储对象等数据的区域③常量池:在堆中分配出来的一块存储区域,位于方法区中,这个方法区式所有线程所共享的内存,这里不做过多描述
基本数据类型和引用类型的区别主要在于基本数据类型是分配在栈上的,而引用类型是分配在堆上的。因为String是一个类,所以Java中的字符串String属于引用数据类型,因此后面带引号的部分是在堆上的
看一个例子:
public class Test01 {
public static void main(String[] args) {
//下面两行代码创建了3个字符串对象,都在常量池当中
String s1 = "abcdef"; //在字符串常量池当中有一个"abcdef"对象
String s2 = "abcdef" + "xy"; //因为已经有了"abcdef"对象,不需要再创建,而是创建"xy"对象,再拼接计算,创建"abcdefxy"对象
String s3 = new String("xy");
//这句代码使用了new关键字。代码中的"xy"是从哪里来的?
//new关键字是实例化对象的,存在堆内存当中,而"xy"是在方法区的字符串常量池当中
//所以,栈中main()方法栈帧中的局部变量s3保存的是一个堆内存对象的地址,堆中对象保存的是常量池"xy"的内存地址
//凡是双引号括起来的都在常量池当中,凡是new实例化的对象都在堆内存当中
}
}s1是一个String类型对象的引用变量,在这里“abcdef”是存储在堆中的字符串常量池中,因此s1指向的就是字符串“abcdef”在字符串常量池中的地址
对于s2,首先已经有了“abcdef”的地址,因此不会再创建,而是创建“xy”对象,再进行拼接成为“abcdefxy”对象
因此,
String s1 = "abcdef";
String s2 = "abcdef" + "xy";这两行代码,一共包含三个对象,在字符串常量池申请了三个空间
String s3 = new String("xy");这行语句,首先s3是栈中的一个引用变量,它指向堆中一个String实例对象的地址,这个String实例对象又指向了字符串常量池中“xy”对象的地址,因此有两次指向
用图来说明就是:
再最后看一个例子巩固以下
public class string {
public static void main(String[] args) {
String s1 = "abc";
String s2 = "abc";
String s3 = new String("abc");
String s4 = new String("abc");
System.out.println(s1 == s2); //输出:true
System.out.println(s1 == s3); //输出:false
System.out.println(s3 == s4); //输出:false
}
}它的输出是
true
false
falses1和s2的地址一样,因为他们都指向了字符串常量池中的同一个地址,s3指向的是堆中的放置普通对象区域的地址,s4同理
因此s1与s3指向的不同,s3与s4指向的也不同
检查字符串是否相等
最先想到的方法就是equals方法
s.equals(t);
"Hello".equals(str);如果相等返回true,不相等返回false
s或者t可以是字符串变量,也可以是字符串字面量
如果想要检测两个字符串是否相等,而不区分大小写,可以使用equalsIgnoreCase方法
"Hello".equalsIgnoreCase("hello");这里注意,最好不要用 “ == ”,要不然很容易出问题,比如下面这种:
public class string {
public static void main(String[] args) {
String str = "Hello World";
String str_sub = str.substring(0, 3);
System.out.println(str_sub);
System.out.println(str_sub == "Hel");
}
}输出的是
Hel
falsesubstring方法的返回值是一个substring对象,注意是对象,因此它的地址不是常量池中“Hel”的地址,而是堆中的一个地址,“==”是比较两个元素地址是否相等的,这么搞肯定会出问题,因此多用.equals()方法
需要时刻注意的是,JVM支持的是字符串常量共享,而不是字符串对象共享
空串与Null串
空串“”是长度为0的字符串。可以调用以下代码检查一个字符串是否为空:
if (str.length() == 0)
或者
if (str.equals(""))String变量还可以存放一个特殊的值,名为null,这表示目前没有任何对象与该变量关联
码点与代码单元
java字符串由char值序列组成,char数据类型是一个采用UTF-16编码表示Unicode码点的代码单元,大多数的常用Unicode字符使用一个代码单元就可以表示,而辅助字符需要一对代码单元表示
我们常用的length方法将返回采用UTF-16编码表示的给定字符串所需要的代码单元数量。例如:
String greeting = "Hello";
int n = greeting.length(); // 这就会显示是5当然讲这个部分一定要有辅助字符才好玩,要不然真没意思比如:
public class CodeUnit {
public static void main(String[] args) {
String str = "Hello";
System.out.println(str.length());
String str1 = " ";
System.out.println(str1.length());
System.out.println(str1.codePointCount(0, 8));
System.out.println(str.charAt(0));
System.out.printf("\\u%04x\n", (int)str1.charAt(0));
System.out.printf("\\u%04x\n", (int)str1.charAt(1));
//如果想得到第i个码点,我们可以用
int index = str1.offsetByCodePoints(0, 1);
System.out.println(index);
int index2 = str1.offsetByCodePoints(2, 1);
System.out.println(index2);
int cp = str1.codePointAt(0);
System.out.printf("\\u%04x\n", (int)cp);
}
}输出的结果是
5
8
4
H
\ud835
\udd46
2
4
\u1d546我们逐个来分析:
第一行是5,因为返回的是码元的长度,对于普通字母来讲,一个码点对应一个码元,因此是多少就是多少
第二行是8,因为这个是辅助字符,每个字符对应一个码点,但是对应两个码元,有四个辅助字符对应四个码点对应8个码元
第三行是4,str1.codePointCount(0, str1.length())返回的是str1对应码点的数量,确切的说是从0开始到 str1.length()-1 这些码元之间的码点的数量
第四、五、六行之间的是charAt方法,它返回的是第几个码元的字符值,但是对于辅助字符来说返回的就不是字符了,应该是一个问号,这里我们有打出了,而是讲它的两个码元转化成了十六进制输出
第七、八两行是指定码元的位置,偏移几个码点都的位置,比如第七行从第0个码元开始,偏移一个码点,到了2,第八行,码元的位置是2,偏移一个码点到了4
第九行str1.codePointAt方法返回的是第i个码元位置码点的unicode值,比如这里 的unicode值为\u1d546,注意,这个str1.codePointAt(index)这个index指的是码元的index位置,如果index为1,返回的值就是\udd46,因为第二个码元位置凑不成一个码点,因此,就返回第二个码元的unicode值,当index为3的时候,就又是\u1d546,很有意思
因此我们想遍历一个字符串,其实是很蓝的啦!
可以先用下面的方法,产生一个int值的“码点流”,再完成遍历
int[] codePoints = str.codePoints().toArray();当然,如果要把一个码点数组转换成一个字符串,我们可以用构造函数
String str = new String(codePoints, 0, codePoints.length)String API
有好多好多,需要的时候再查吧,背也背不下来
构建字符串
推荐使用StringBuilder,像这样:
StringBuilder builder = new StringBuilder();当每次需要添加一部分内容的时候,就调用append()方法
那么这样跟普通的字符串拼接有什么好处呢?
这里引用下面的博文:https://blog.csdn.net/weixin_44681025/article/details/122993472
string的字符串操作都是废弃已有的对象,开辟一个新的内存空间创建一个新的对象,比如一个
string str = "字符串"
str += "a"这样操作后就会有好几个字符串对象,并且还要回收“字符串”, 但是用StringBuilder就不会,它是一个字符串工厂,不断地丢字符串到里面进行拼接,它也不会创建新的对象,而是最后调用ToString()的时候才作一次创建字符串的操作,这样的大量操作的时候效率就很高
总结的说就是:
- 简化字符串常量池的个数,节省内存
- StringBuilder相当于一个池子,可以存放很多已有的字符串,使用时可以以此获得很长的字符串,从而优化程序
- JDK底层使用StringBuilder实现字符串拼接
|
|



 发表于 2023-6-9 13:04:37
发表于 2023-6-9 13:04:37